Technical overview
Table of Contents
# Main components
# Migration
A migration covers transactional changes and operations you want to track in your database. Mongock uses the concept of ChangeUnit, which is a single migration file. A migration can execute multiple ChangeUnits during start up.
As Mongock promotes a code-first approach for migrations, a ChangeUnit is materialized as a Java class. Using the @ChangeUnit annotation you will be able to implement your unit of migration that will be stored in the Mongock state records.
For more information, visit the Migration page
Note that the @ChangeLog and @ChangeSet annotations have been deprecated in Version 5 and replaced by the new annotation @ChangeUnit
# Driver
It represents the persistence layer. Everything that needs to be persisted is passed to the driver. It's basically used by the runner to persist and check the migration history and work with the distributed lock.
Mongock splits the drivers in driver families, grouped by databases. Then, within a driver family, it may provide multiple drivers for different connection library and versions.
For example, in the case of MongoDB, Mongock provides 4 drivers for:
- org.mongodb » mongodb-driver-sync
- org.mongodb » mongo-java-driver
- org.springframework.data » spring-data-mongodb(v3.x)
- org.springframework.data » spring-data-mongodb(v2.x)
The Mongock architecture is designed in such a way that allows you to combine any driver with any runner. For example, you may want to use a Mongock driver for springdata with the standalone runner(no framework).
For more information, visit the Driver page
# Runner
The runner is the orchestator component dealing with the process logic, configuration, dependencies, framework and any environmental aspect. It’s the glue that puts together all the components as well as the decision maker. It takes the migration, driver and framework, and run the process.
Mongock provides different runner for multiple frameworks(standalone, Springboot, Micronaut...) and it can be combined with any driver
For more information, visit the Runner page
# Mongock process
In a nutshell, the mongock migration process takes all the pending migration changes and executes them in order.
Mongock is designed to run successfully the entire migration or fail. And the next time is executed, it will continue from where the migration was left(the failed ChangeUnit).
Normaly the Mongock process is placed in the application startup, so it ensures the application is deployed only once the migration has been successfully finished in order to gurantee the consistency between the code and the data.
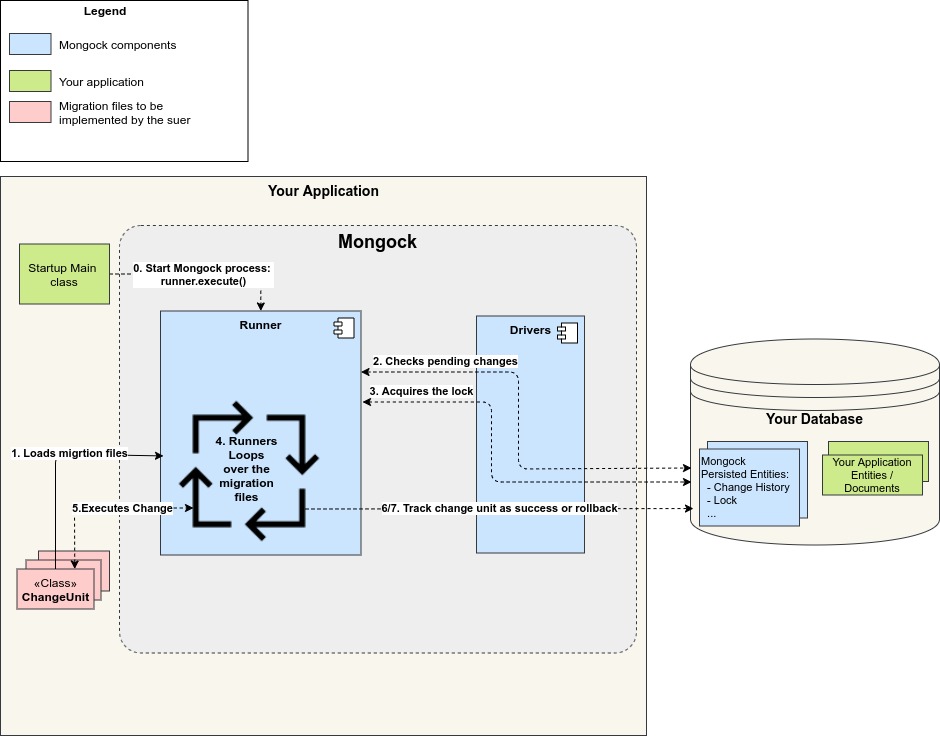
# Process steps
Mongock process follows the next steps:
- The runner loads the migration files(changeUnits).
- The runner checks if there is pending change to execute.
- The runner acquires the distributed lock through the driver.
- The runner loops over the migration files(changeUnits) in order.
- Takes the next ChangeUnit and executes it.
- If the ChangeUnit is successfully executed, Mongock persists an entry in the Mongock change history with the state SUCCESS and start the step 5 again.
- If the ChangeUnit fails, the runner rolls back the change. If the driver supports transactions and transactions are enabled, the rollback is done natively. When the driver does not support transactions or transactions are disabled, the method @RollbackExecution is executed. In both cases the ChangeUnit failed, whereas in the latter option, and entry is added in the changelog that a change has been rolled back.
- If the runner acomplished to execute the entire migration with no failures, it's considered successful. It releases the lock and finishes the migration.
- On the other hand, if any ChangeUnit fails, the runner stops the migration at that point and throws an exception. When Mongock is executed again, it will continue from the failure ChangeUnit(included).
# Architecture